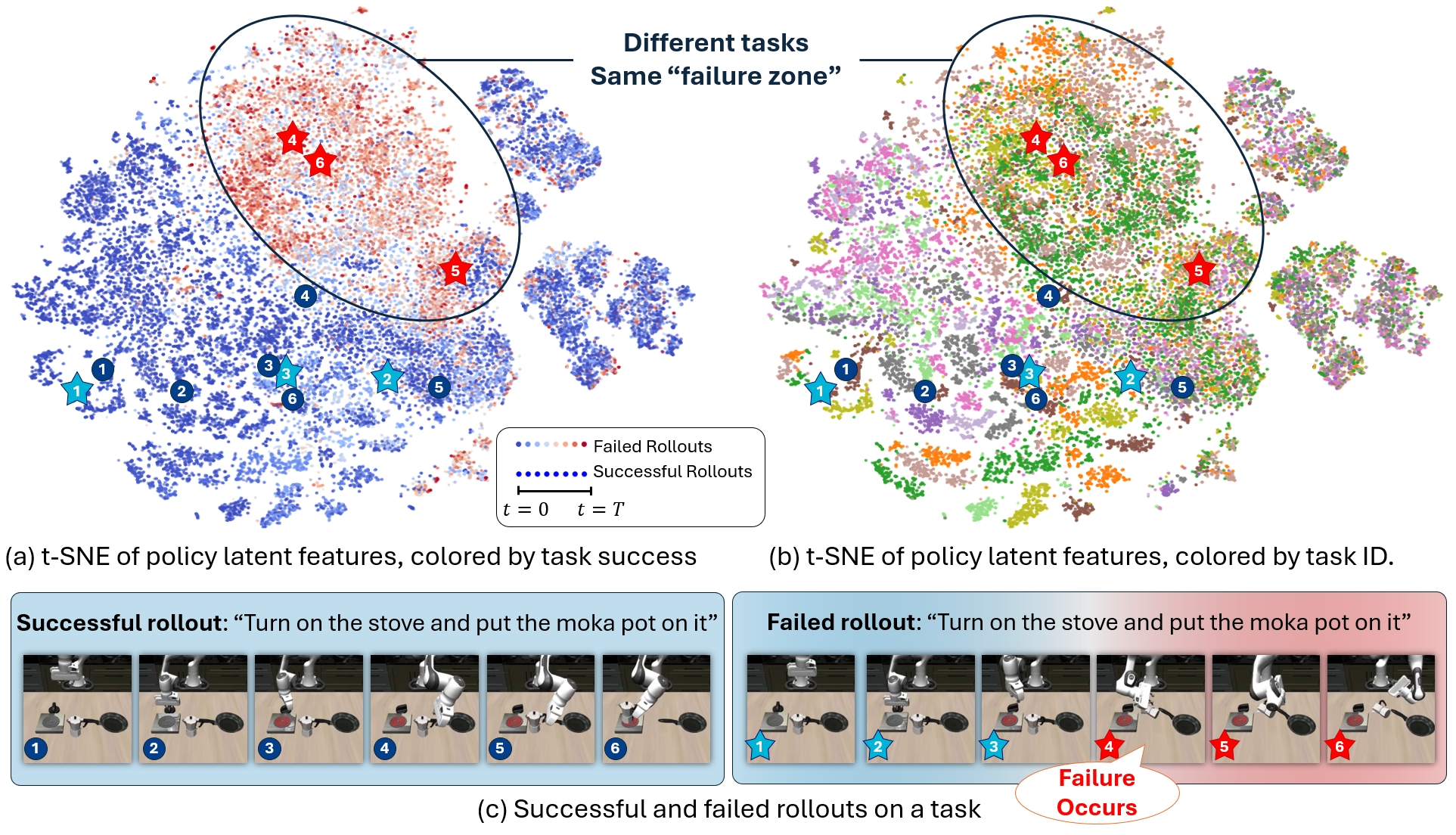
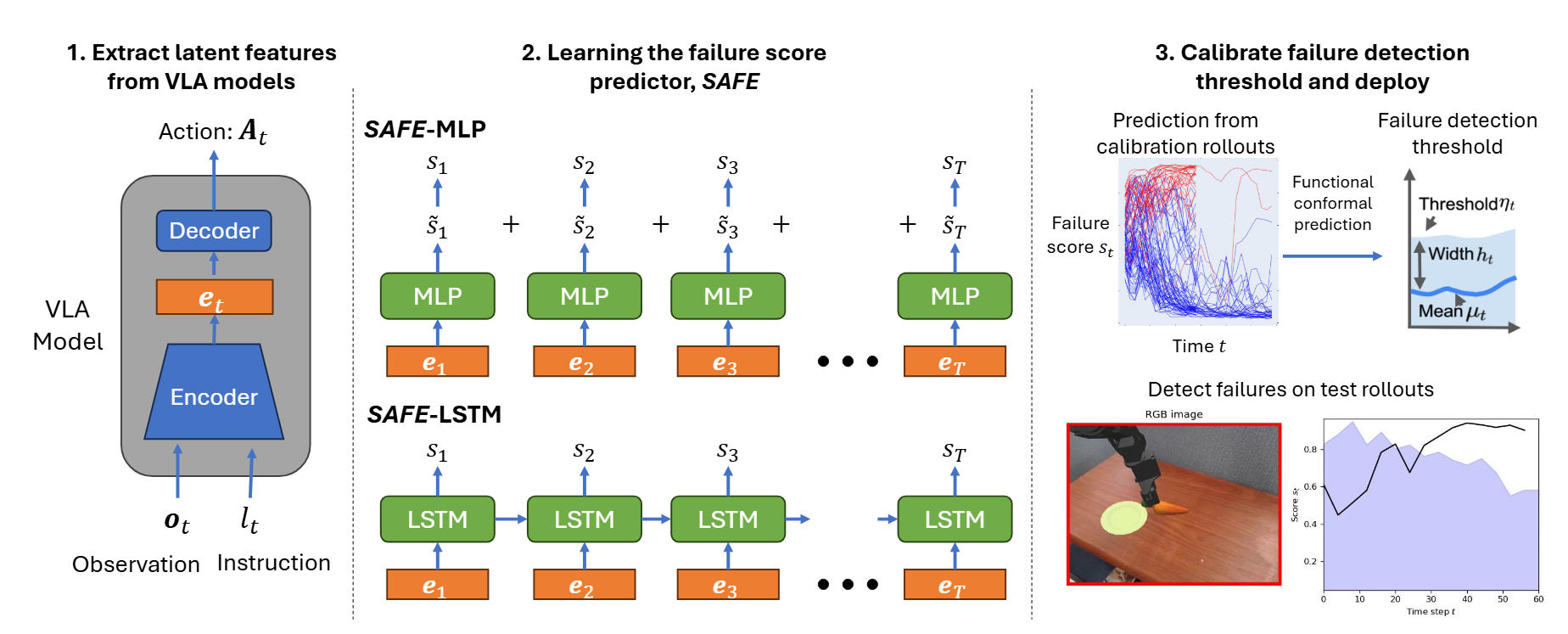
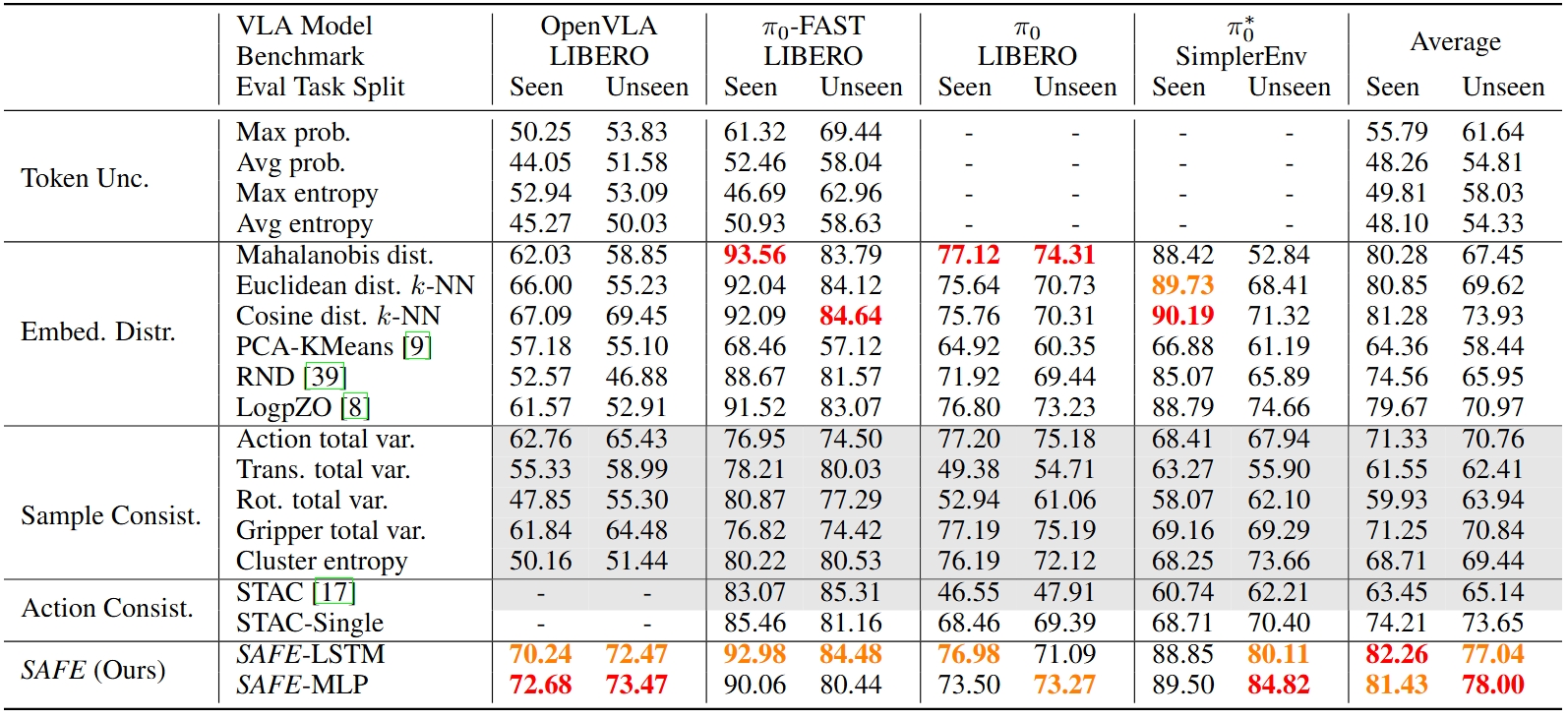
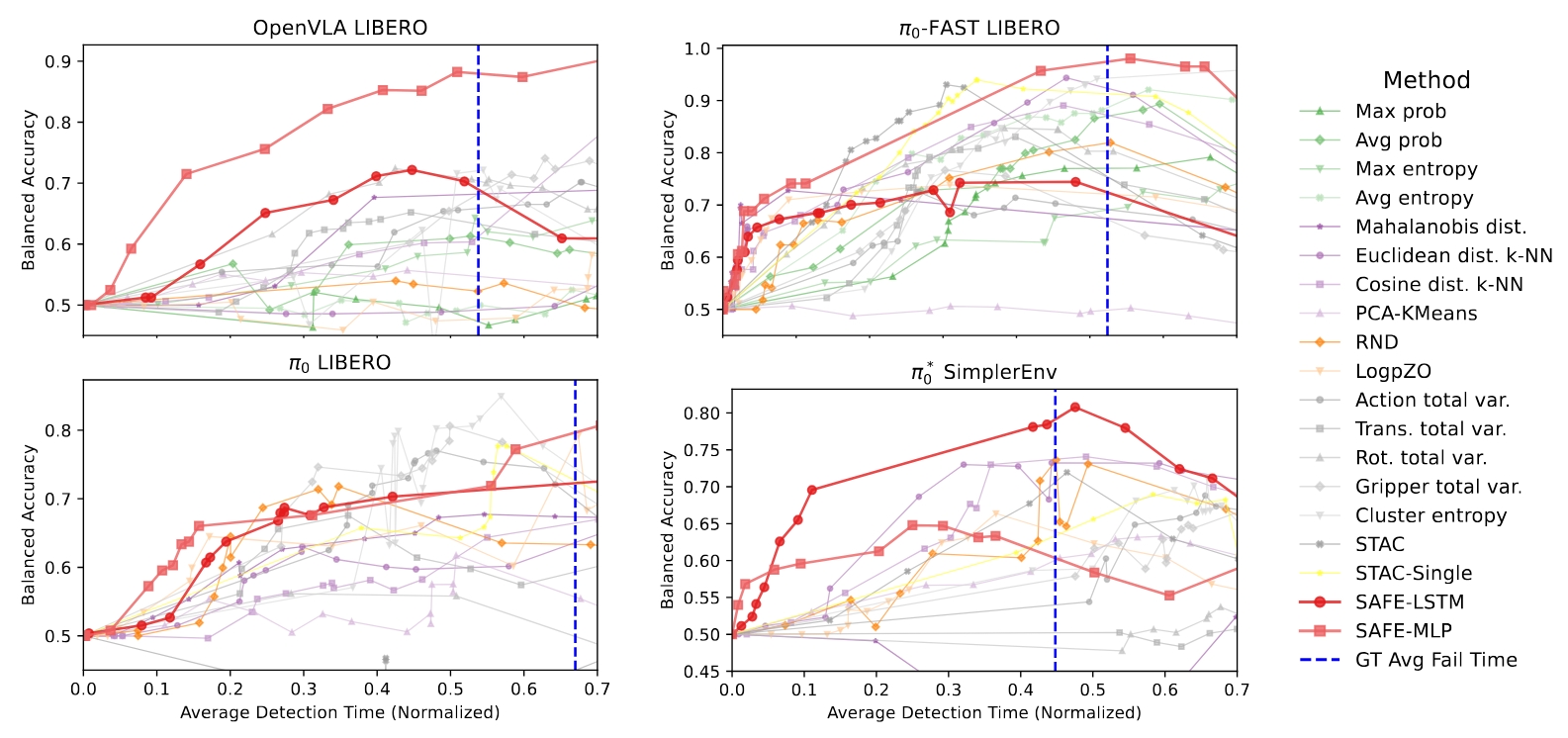
While vision-language-action models (VLAs) have shown promising robotic behaviors across a diverse set of manipulation tasks, they achieve limited success rates when deployed on novel tasks out-of-the-box. To allow these policies to safely interact with their environments, we need a failure detector that gives a timely alert such that the robot can stop, backtrack, or ask for help. However, existing failure detectors are trained and tested only on one or a few specific tasks, while VLAs require the detector to generalize and detect failures also in unseen tasks and novel environments. In this paper, we introduce the multitask failure detection problem and propose SAFE, a failure detector for generalist robot policies such as VLAs. We analyze the VLA feature space and find that VLAs have sufficient high-level knowledge about task success and failure, which is generic across different tasks. Based on this insight, we design SAFE to learn from VLA internal features and predict a single scalar indicating the likelihood of task failure. SAFE is trained on both successful and failed rollouts, and is evaluated on unseen tasks. SAFE is compatible with different policy architectures. We test it on OpenVLA, π0, and π0-FAST in both simulated and real-world environments extensively. We compare SAFE with diverse baselines and show that SAFE achieves state-of-the-art failure detection performance and the best trade-off between accuracy and detection time using conformal prediction.